The constraint on your AI ambitions for the next two years won't be chips or budget. It's electricity — and the lead time to get it is measured in years, not quarters.
For two decades, cloud capacity behaved like water from a tap. You needed more, you provisioned more, the bill arrived, and the only real discipline was not wasting what you'd turned on. An entire profession — FinOps — grew up around that last problem: stop paying for capacity you don't use. It was a spending problem, and spending problems are comfortable because money is something you control.
That era is closing, and the thing replacing it is far less comfortable. The binding constraint on large-scale compute in 2026 is not money and not even chips. It's power. Roughly half of the US data-center capacity planned for this year is delayed or cancelled, and the reasons are physical: grid interconnections that take up to four years, severe shortages of transformers and switchgear, and local opposition to new builds. Of around 16 gigawatts planned, only about 5 has actually entered construction.
The detail that should stop a CTO mid-sentence: Microsoft has acknowledged it has AI GPUs sitting in inventory because it lacks the power to install them. The chips are in the building. There isn't enough electricity to turn them on. When the most resourced cloud operator on earth is bottlenecked on watts rather than silicon, the assumption that capacity is always one purchase order away no longer holds.
The constraint moved, and most roadmaps didn't notice
The mental model most infrastructure plans still run on is chip-scarcity: GPUs are the rare thing, and if you can secure allocation, you're set. That was true in 2023 and 2024. It's now misleading. GPU supply is still tight, but it's tight downstream of power — cloud GPU availability is expected to stay constrained through mid-2027 not because nobody can make the chips, but because the facilities to house and power them aren't coming online on schedule.
This inverts how you should reason about capacity risk. A signed contract for GPU instances is a claim on hardware that may be waiting on a substation. Lead times you used to measure in weeks now depend on grid interconnect queues measured in years. The roadmap that assumes elastic, on-demand scale for large AI workloads is quietly planning around a resource that has stopped being elastic.
Visual 1 — Planned vs. energized US data-center capacity, 2026
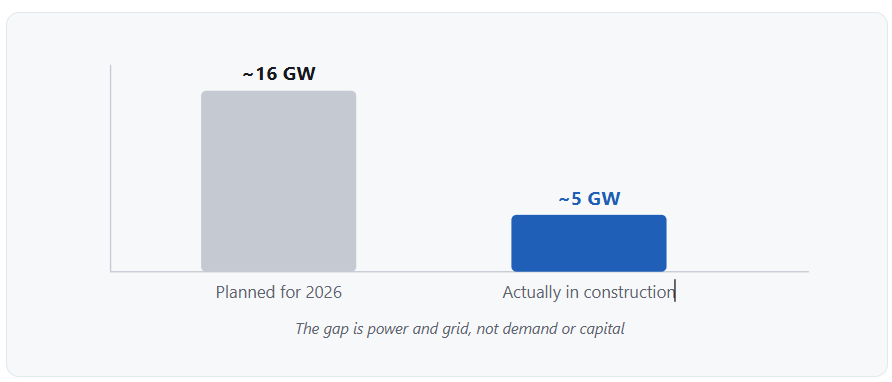
Source: 2026 US data-center capacity reporting. Roughly half of planned capacity is delayed or cancelled; the binding constraint is power delivery — transformers, switchgear, and grid interconnects — not chip supply.
What this does to the cost and shape of cloud
Scarcity reprices things. When power is the bottleneck, the premium shifts to whoever already has it — operators with secured energy contracts, sites near generation, regions with spare grid headroom. Expect location to matter again in a way it hasn't since the early cloud era. The cheapest compute will not be wherever you prefer; it will be wherever the electrons are, which may be a different country and a different latency profile than your architecture assumes.
It also revives a strategy the cloud was supposed to have killed: owning your own power. Bring-your-own-power arrangements — co-locating near generation, signing direct energy deals — are becoming attractive again despite their complexity, because a guaranteed megawatt is worth more than a flexible contract that can't be fulfilled. The pendulum that swung fully toward "rent everything" is wobbling back toward "secure the scarce input yourself."
For fifteen years the smart move was to stop owning infrastructure. When the scarce resource becomes electricity, the smart move starts to include owning access to it again.
What this means for leaders
Treat power availability as a first-class planning input. When you model a large AI workload, the question is no longer just "what will the instances cost?" It's "where is the capacity actually energized, and on what timeline?" Add power and grid lead times to the same risk register where you track chip allocation and budget.
Diversify by region and operator, deliberately. Single-region, single-provider plans for heavy compute now carry a delivery risk that has nothing to do with the provider's competence — it's about whether their next site gets powered on schedule. Build optionality across geographies where grid headroom differs.
Separate the workloads that must scale from the ones that can wait. Not every model needs frontier-scale capacity. The discipline of the next two years is matching genuinely power-hungry workloads to secured capacity, while keeping everything else efficient enough to run in the headroom you already have. That's FinOps maturity meeting physical reality — efficiency is no longer about the bill alone; it's about fitting inside a supply that won't stretch on demand.
The cloud sold a promise of infinite, instant scale, and for a long time it kept that promise. The promise didn't break because the technology failed. It broke because someone has to build the power plants, and that takes longer than a procurement cycle. The roadmaps that account for it will ship. The ones that assume the tap still runs will find their GPUs, like Microsoft's, waiting in a room with no power.
A BusinessInfomatics original. Figures from 2026 US data-center capacity analyses, Data Center Dynamics reporting on idle GPU inventory, and infrastructure-investment commentary on power and grid constraints.